Fitting measurement error models and missing data imputation models in INLA is not trivial, and requires several workarounds in order to fit the model. At the same time, a Bayesian hierarchical framework is very attractive for modeling these types of data, since the hierarchical model structure allows us to describe how the data were collected, and any errors they may have, through the model specification. By supplying informative priors, we may be able to adjust for biases due to these errors, and propagate any uncertainty they cause. Until recently, it has been complicated to implement these kinds of models in R-INLA. This package provides a helpful interface that makes measurement error and missing data modelling in R-INLA much more feasible.
Installation
You can install the package directly from CRAN with:
install.packages("inlamemi")Alternatively, you can install the development version of inlamemi from GitHub with:
# install.packages("devtools")
devtools::install_github("emmaSkarstein/inlamemi")When should I use this package?
This package is designed for fitting models where you have one covariate that has classical measurement error, Berkson measurement error, missing observations, or any combination of these three. That could mean that you only have missing data, and if so this package can do missing data imputation.
The model itself must be of the class of models that is possible to fit with R-INLA. That means that it can be used for most common regression types, like linear regression and logistic regression, and you can include as many error free covariates as needed. You can also include random effects, the same way as you would normally include such effects in R-INLA. Interaction effects with the error prone variable are also dealt with by the package. It is even possible to fit models for cases where you have multiple variables with error or missingness, though this is something one should be careful with, as these models rely very heavily on the priors you give them.
Overview of examples
Examples of how to use the package can be found in the vignettes.
| Vignette name | Likelihood for MOI | Error type | Other features |
|---|---|---|---|
| Influence of systolic blood pressure on coronary heart disease | Binomial | Classical | Repeated measurements of error prone variable, interaction effect with error variable |
| Survival model with repeated systolic blood pressure measurements | Weibull survival | Classical, missing | Repeated measurements of error prone variable |
| Simulated examples (multiple examples) | Gaussian, Binomial, Poisson | Berkson, classical, missing | Random effect(s) in the model of interest, interaction effects |
| Multiple variables with measurement error and missingness | Gaussian | Classical | Multiple mismeasured covariates |
| Modifying the default plot | Shows how to modify the plot produced by the plot.inlamemi function. |
||
| How are the models structured? | A deep dive into how the data is structured in order to correctly fit the model. | ||
How to avoid using inlamemi |
An illustration of how the models can be fit without using inlamemi, in case you would like to extend the model in a way beyond what inlamemi will allow. This vignette can also be useful if you are familiar with R-INLA and want to understand how the models are structured. |
Quick guide: How can I use this package?
The dataset simple_data is included in the package, and is a very simple simulated data set, used to illustrate the package. In this data set, we have a response variable , an error free covariate , and a covariate that is observed with classical error, Berkson error and missingness, called . We wish to fit the model
but adjusting for all the errors in .
First load the package:
Next, we need to specify the formula for the main model and the formula for the imputation model. This is done in the standard way in R:
main_formula <- y ~ x + zFor the imputation model, we take advantage of any correlation between and the error free covariate , so the imputation model will be
We write that as
imputation_formula <- x ~ zWhen adjusting for measurement error, we are completely dependent on having some information about the measurement error variances (for the classical error) and (for the Berkson error), since the size of this variance will affect how the estimates are biased. We can gain information about these variances in a few different ways, if repeated measurements have been made then these can be put directly into the model to estimate the error variance, or if we have some expert knowledge about the error size, then that can be used to specify an informative prior for the variance (or precision, since in INLA the precision is used, rather than the variance).
In this case, since we have in fact simulated the data ourselves, we know that the error variances are in both cases close to 1, so we specify priors that have modes at 1.
In the fit_inlamemi function we also need to specify the likelihood for the model of interest, which in this case is Gaussian.
simple_model <- fit_inlamemi(data = simple_data,
formula_moi = main_formula,
formula_imp = imputation_formula,
family_moi = "gaussian",
error_type = c("berkson", "classical", "missing"),
prior.prec.moi = c(10, 9),
prior.prec.berkson = c(10, 9),
prior.prec.classical = c(10, 9),
prior.prec.imp = c(10, 9),
prior.beta.error = c(0, 1/1000),
initial.prec.moi = 1,
initial.prec.berkson = 1,
initial.prec.classical = 1,
initial.prec.imp = 1)Once we have fit the model, we can view the summary:
summary(simple_model)
#> Formula for model of interest:
#> y ~ x + z
#>
#> Formula for imputation model:
#> x ~ z
#>
#> Error types:
#> [1] "berkson" "classical" "missing"
#>
#> Fixed effects for model of interest:
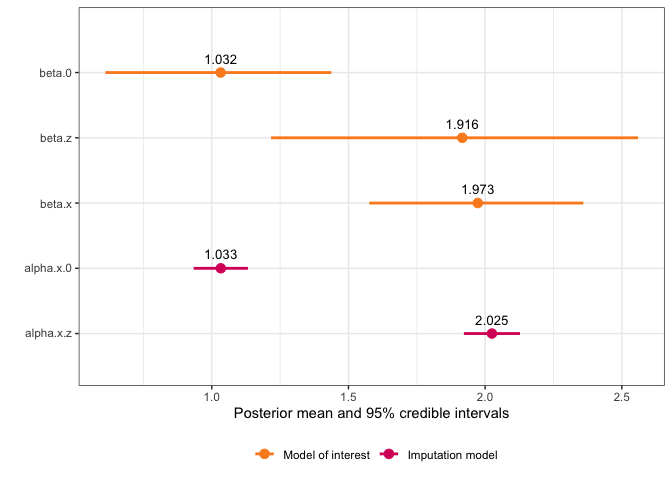
#> mean sd 0.025quant 0.5quant 0.975quant mode
#> beta.0 1.029408 0.2180168 0.6085174 1.028547 1.440033 1.022823
#> beta.z 1.910018 0.3864093 1.2097061 1.899498 2.565503 1.907050
#>
#> Coefficient for variable with measurement error and/or missingness:
#> mean sd 0.025quant 0.5quant 0.975quant mode
#> beta.x 1.973031 0.1955614 1.582293 1.97498 2.352271 1.983233
#>
#> Fixed effects for imputation model:
#> mean sd 0.025quant 0.5quant 0.975quant mode
#> alpha.x.0 1.033073 0.05060773 0.9337902 1.033081 1.132311 1.033081
#> alpha.x.z 2.024723 0.05227029 1.9222514 2.024706 2.127294 2.024706
#>
#> Model hyperparameters (apart from beta.x):
#> mean sd 0.025quant 0.5quant
#> Precision for model of interest 1.1292120 0.3549186 0.5731591 1.0821470
#> Precision for x berkson model 1.1249792 0.3327340 0.6030345 1.0810229
#> Precision for x classical model 0.9248817 0.1063716 0.7351107 0.9181755
#> Precision for x imp model 0.9778644 0.1225878 0.7574632 0.9707262
#> 0.975quant mode
#> Precision for model of interest 1.955436 0.9960169
#> Precision for x berkson model 1.900730 0.9994948
#> Precision for x classical model 1.153382 0.9036513
#> Precision for x imp model 1.239320 0.9574767And we can use the default plot function to see a plot of the fixed effects and estimated coefficient for the variable with error:
plot(simple_model)